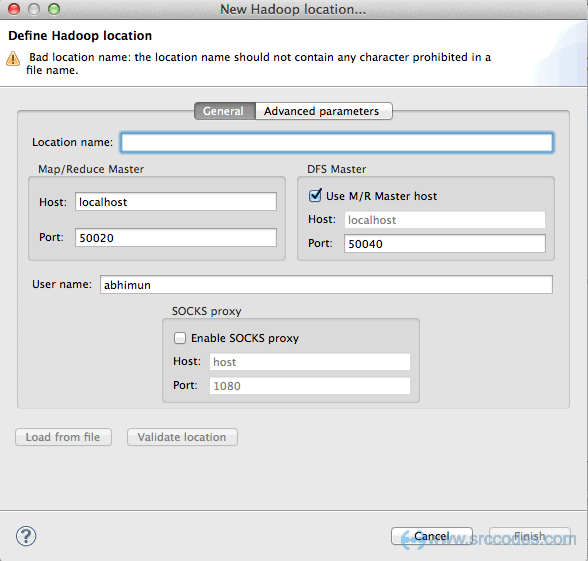
Simple Tips About How To Build Hadoop
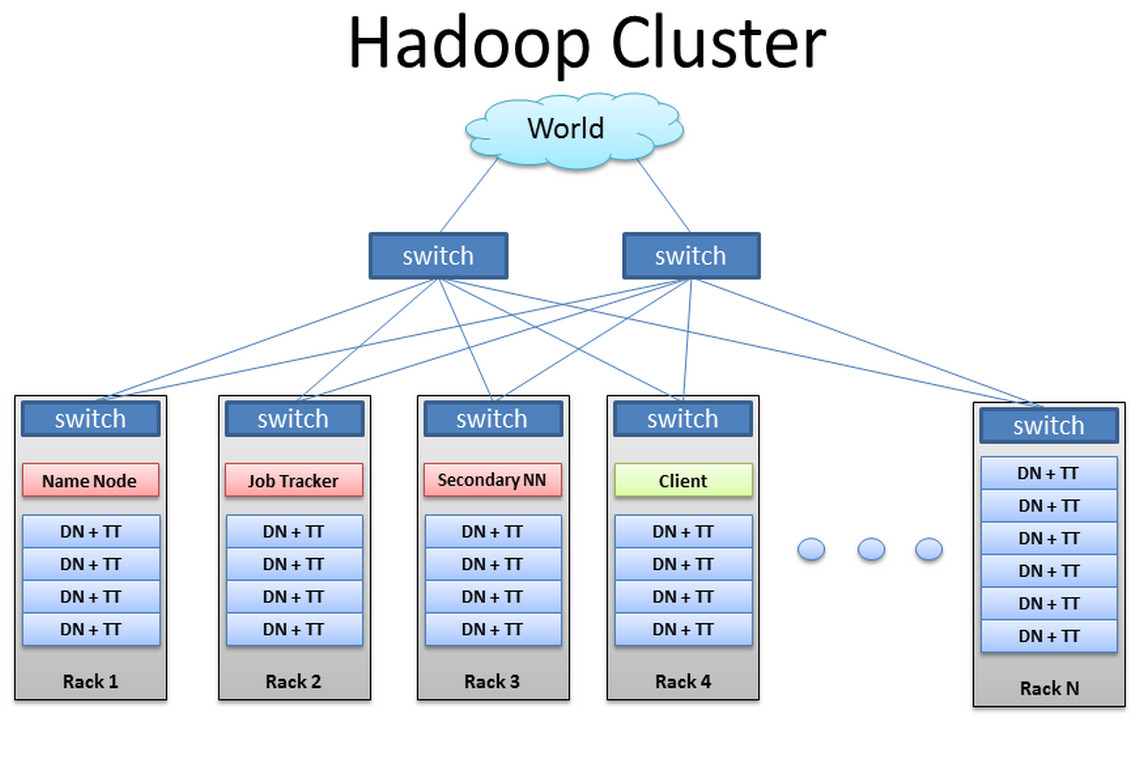
What Is Hadoop Clusters?
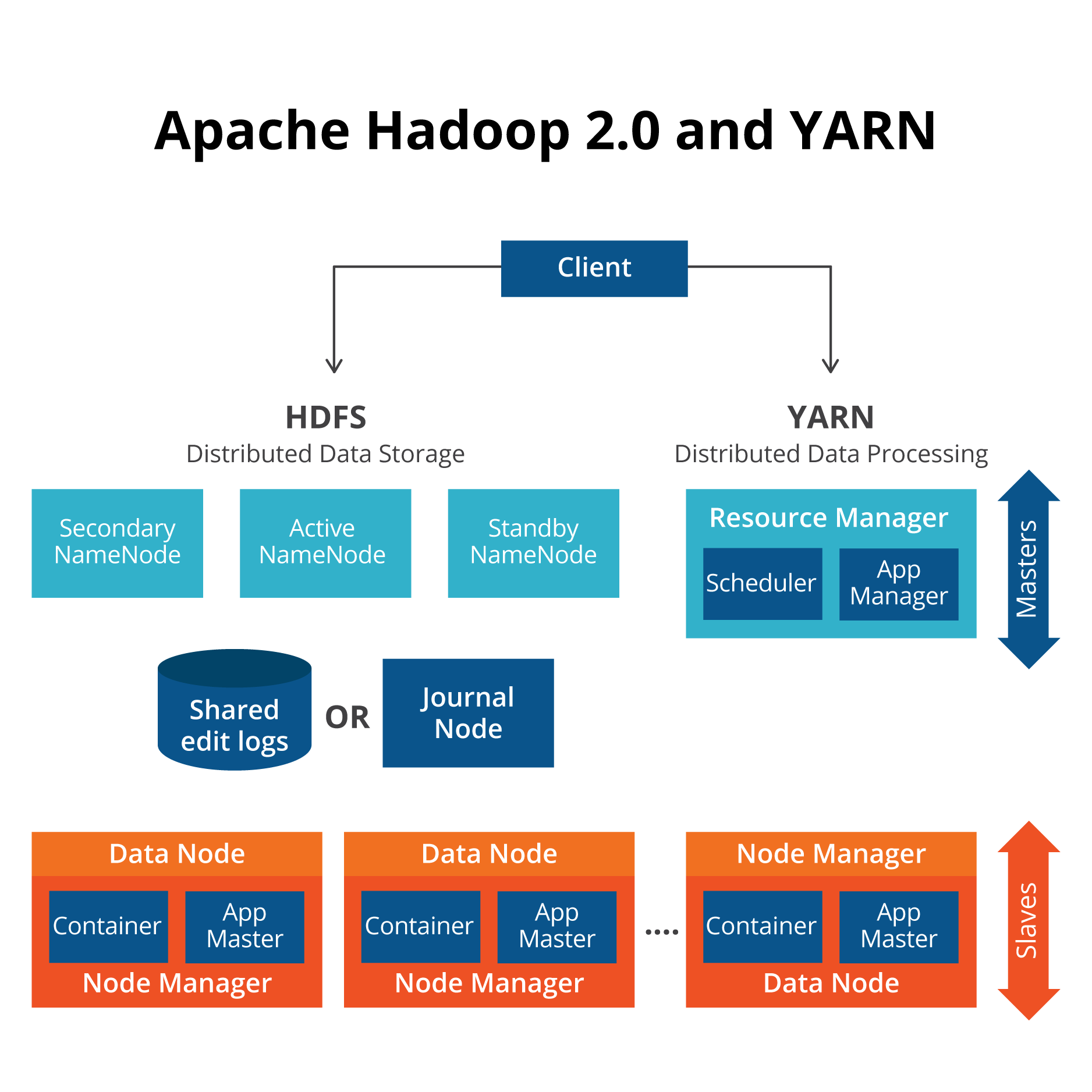
An Introduction To Hadoop Architecture Bmc Software Blogs

Why Should You Build A Career In Hadoop? Infographic Website
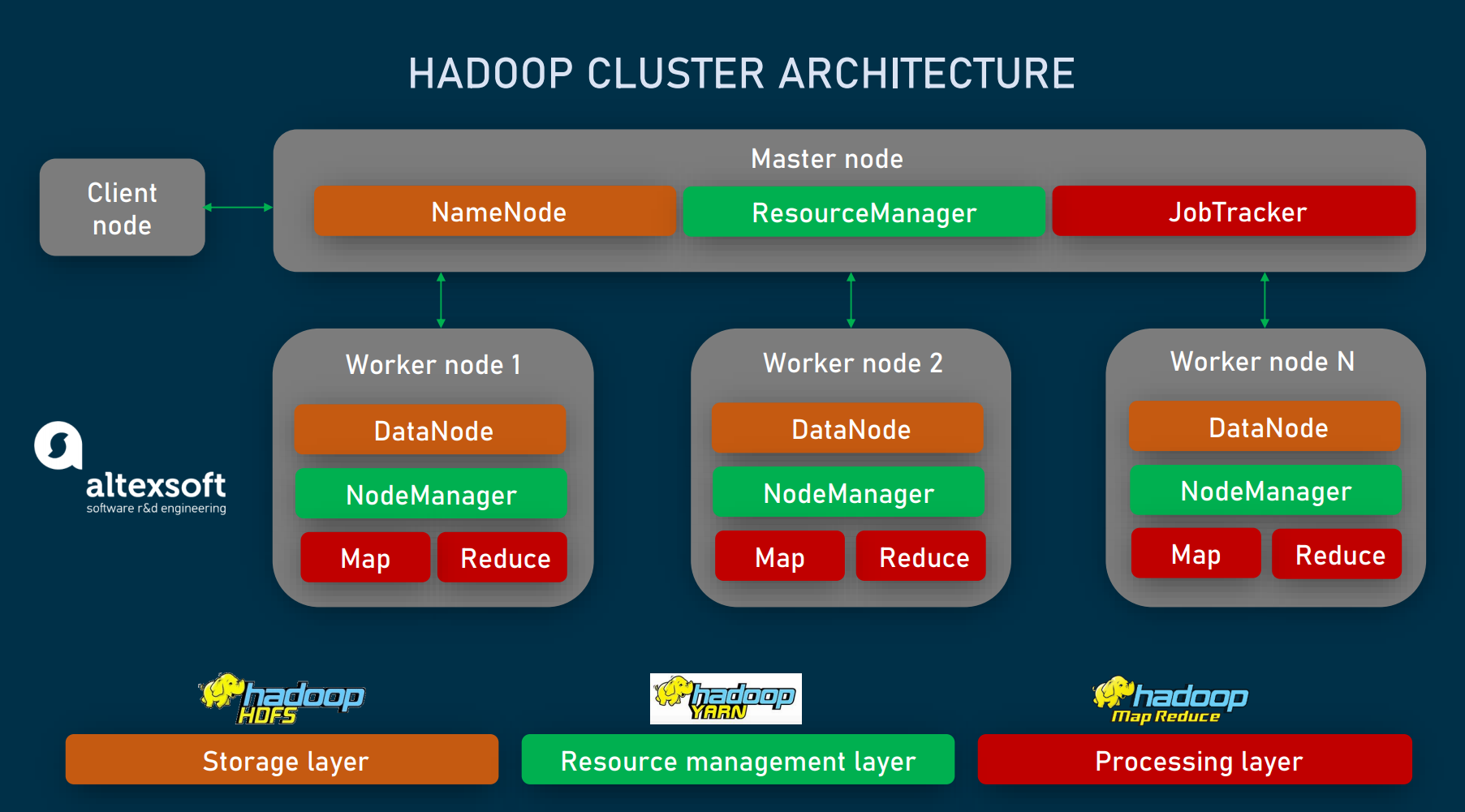
Apache Hadoop Vs Spark Main Big Data Tools Explained

How To Install Hadoop In Standalone Mode On Ubuntu 18.04 Digitalocean
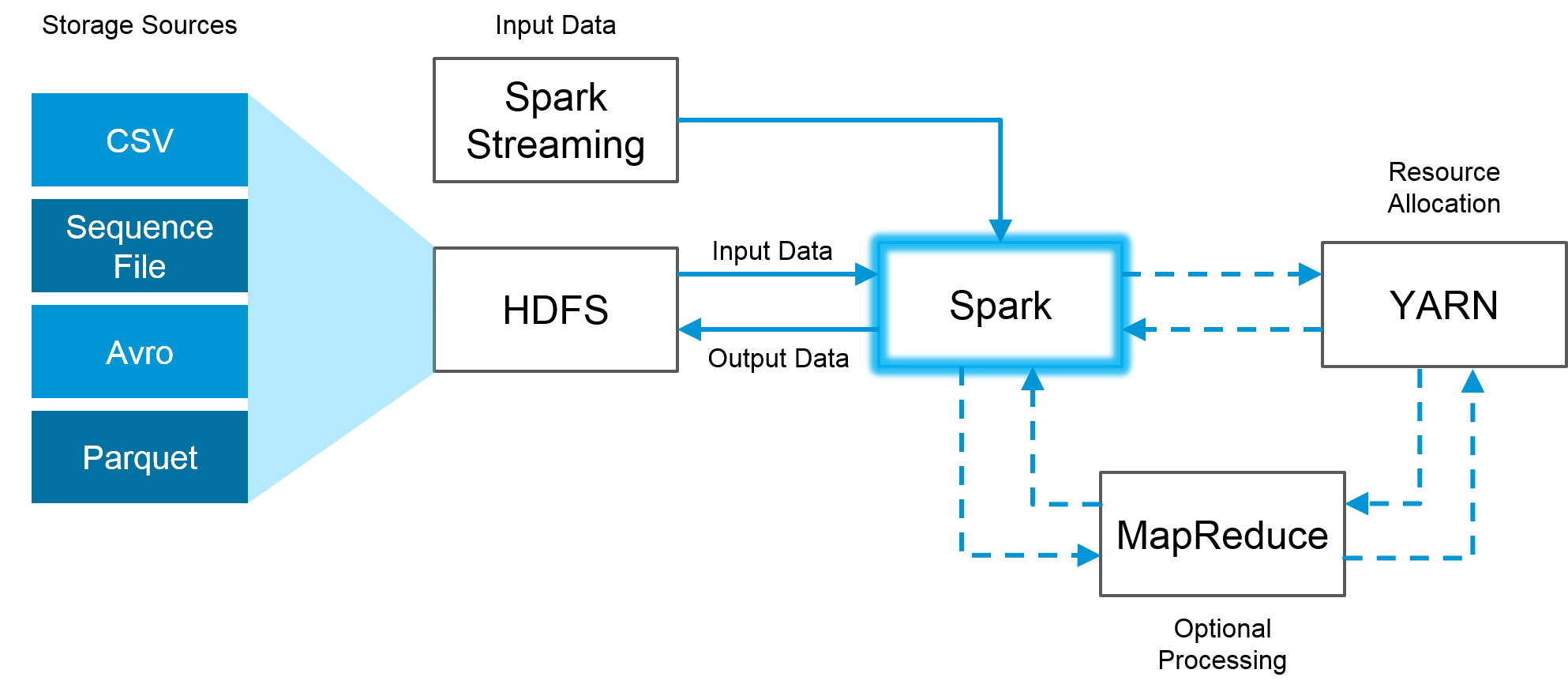
Building A Realtime Big Data Pipeline (2 Spark Core, Hadoop, Scala
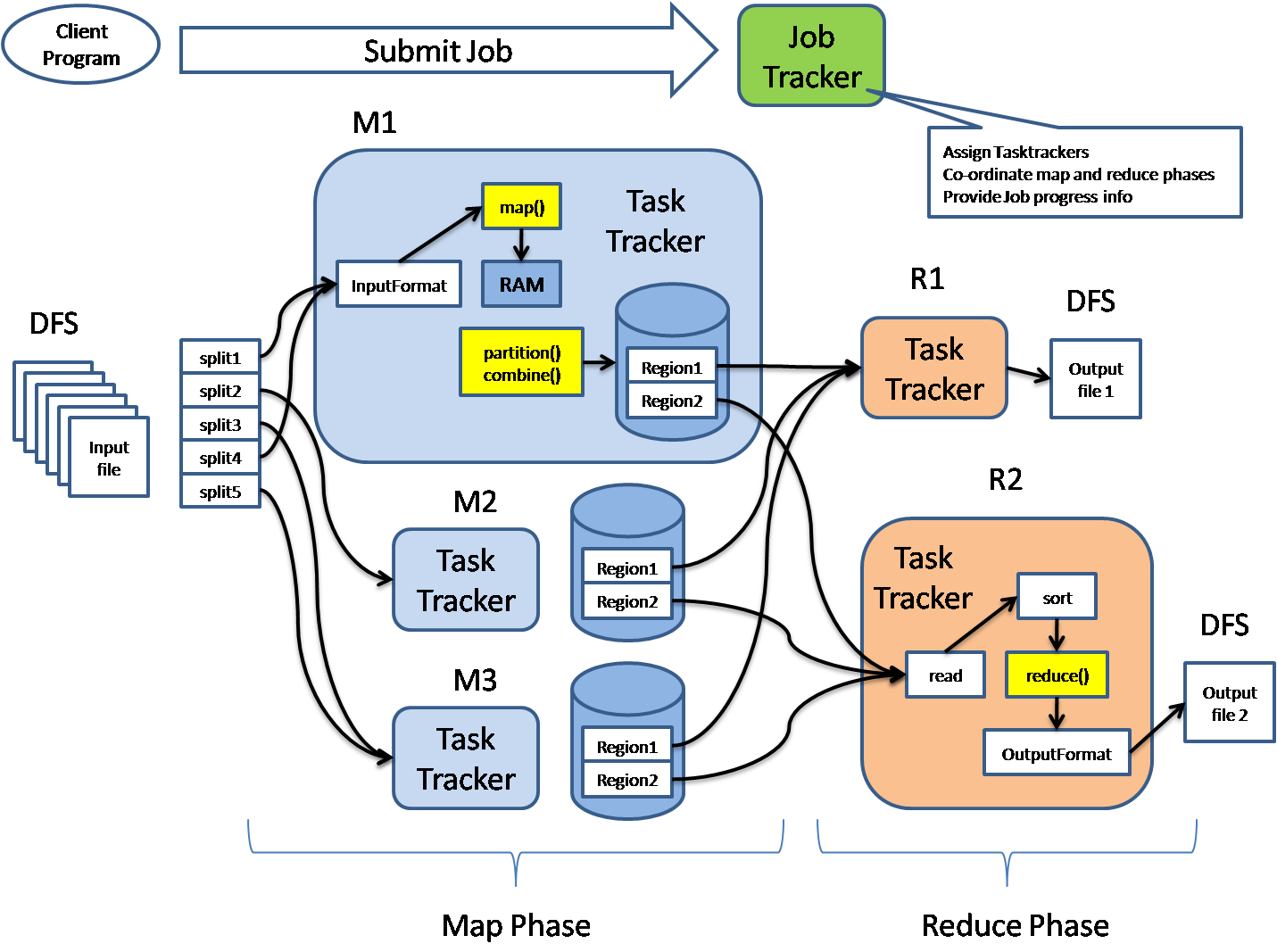
9 how to build hadoop from source without errors preliminary downloads:
How to build hadoop. Start dockerd.exe process if not started automatically via services. Open your downloaded hadoop source code file, i.e. Below i’ll outline the steps i took to build apache hadoop from source on macos in august of 2017.
Hadoop 2.x vs hadoop 3.x; For more information, see create an. The main steps are:
Evolution of hadoop; Best practices for building hadoop cluster. This version was released on july 14 2020.
Wls (windows subsystem for linux) is not required. An ecs linux instance is created. We then copy the package to the worker nodes.
Save this reel for future reference complete roadmap to learn data science in 2024 1. I also published another article with very detailed steps about how to compile and build native hadoop on windows: This blog takes a longer path to configure highly available big data platform on hadoop using purely command line.
It also contains the prerequisites for each release. For different releases, the dependencies/prerequisites may be different. After setting up hadoop on the master node, we copy the settings to the three worker nodes.
Installation installing a hadoop cluster typically involves unpacking the software on all the machines in the cluster or installing it. For example, hadoop 3.2.2 requires protocalbuffer 3.0. You need to download the following before you begin.
The official location for hadoop is the apache git repository. Now the point is how to manage the dependent jars. Maven is one way of doing it.
In the repository of hadoop on github, building.txtfile provides the high level steps to build hadoop on different environments. First of all, you need the hadoop source code. 0:00 / 1:47:09 🔥post graduate program in data engineering:
See the hadoop wiki for known good versions. Next, we access each worker node, unpack the. Installing and setting up hadoop.

Overview Of The Hadoop Ecosystem Apache Hive Essentials Second Edition

What Is Hadoop And How Does Work? Programming Cube
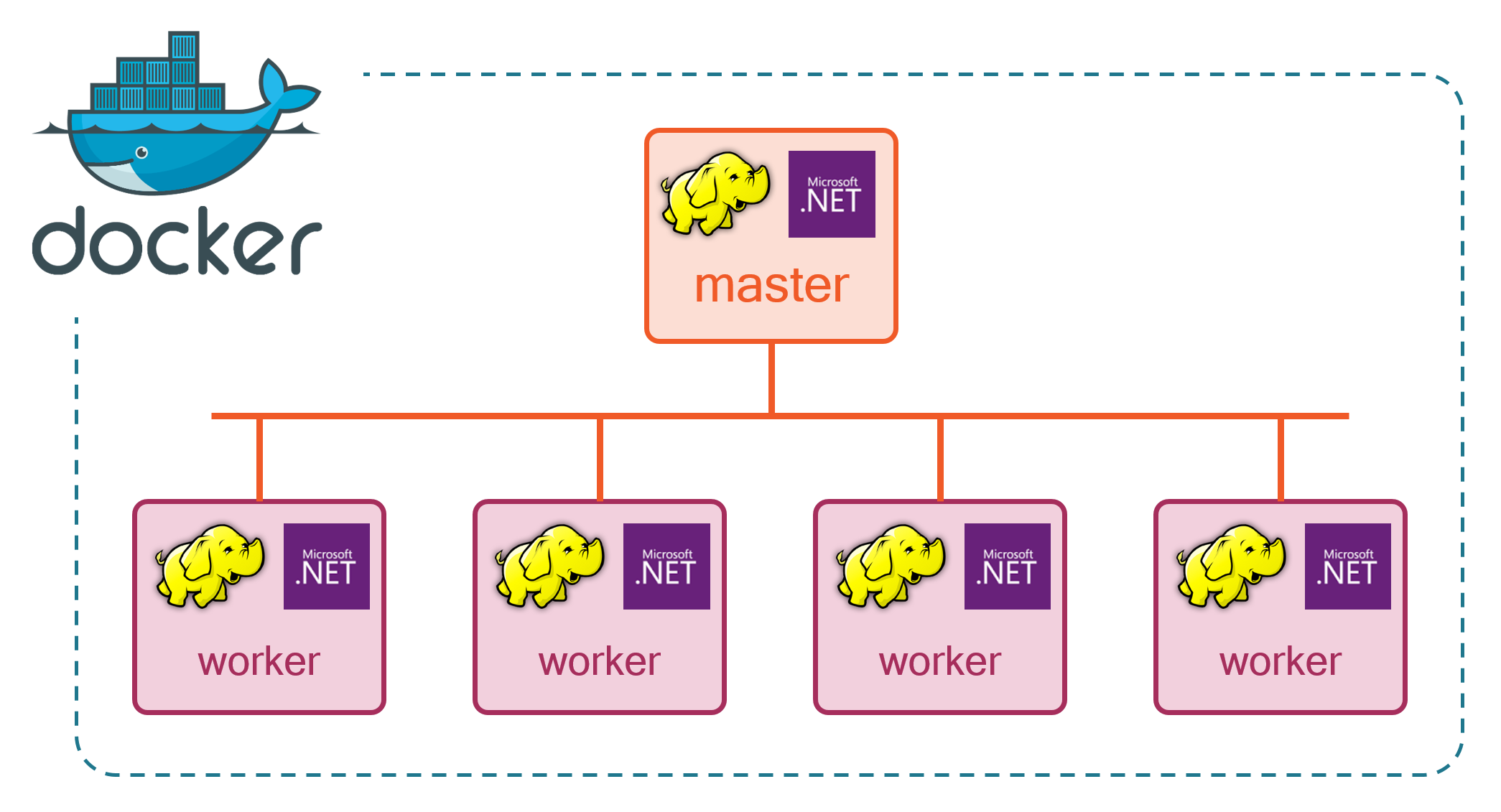
Hadoop And A Match Made In Docker
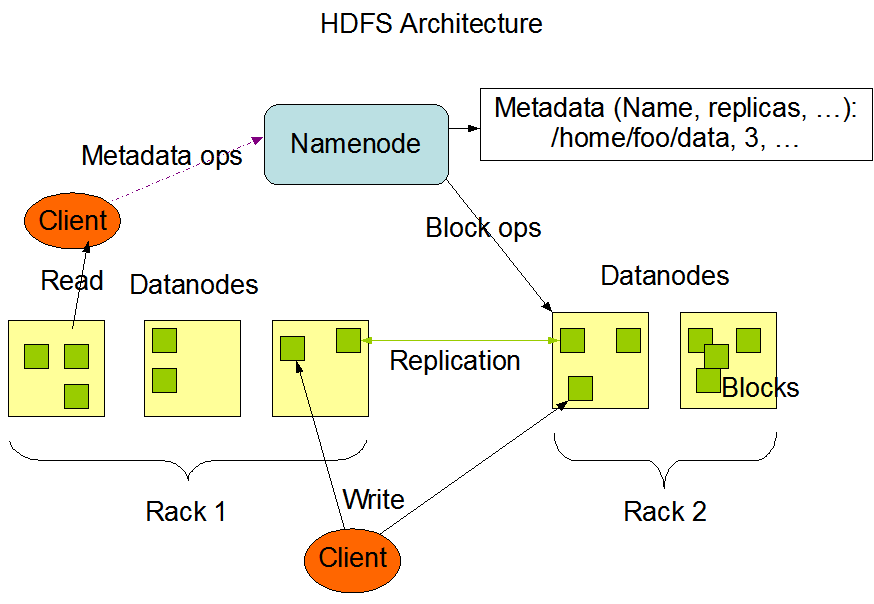
Big Data Hadoop Architecture And Components Tutorial
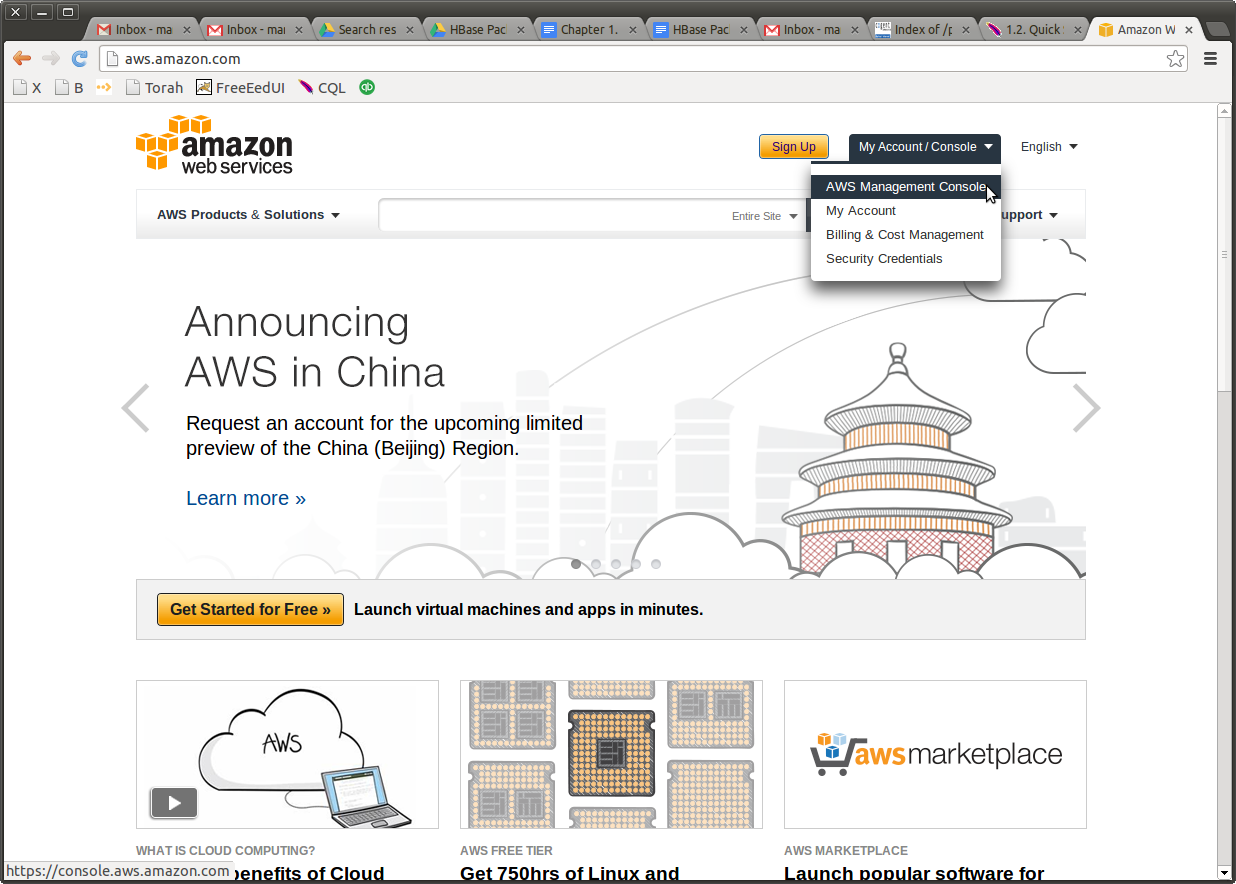
Shmsoft Blog How To Build A Hadoop Cluster On Aws
Things To Code

Compression In Hadoop Icircuit

Hadoop Cluster Build Your Own
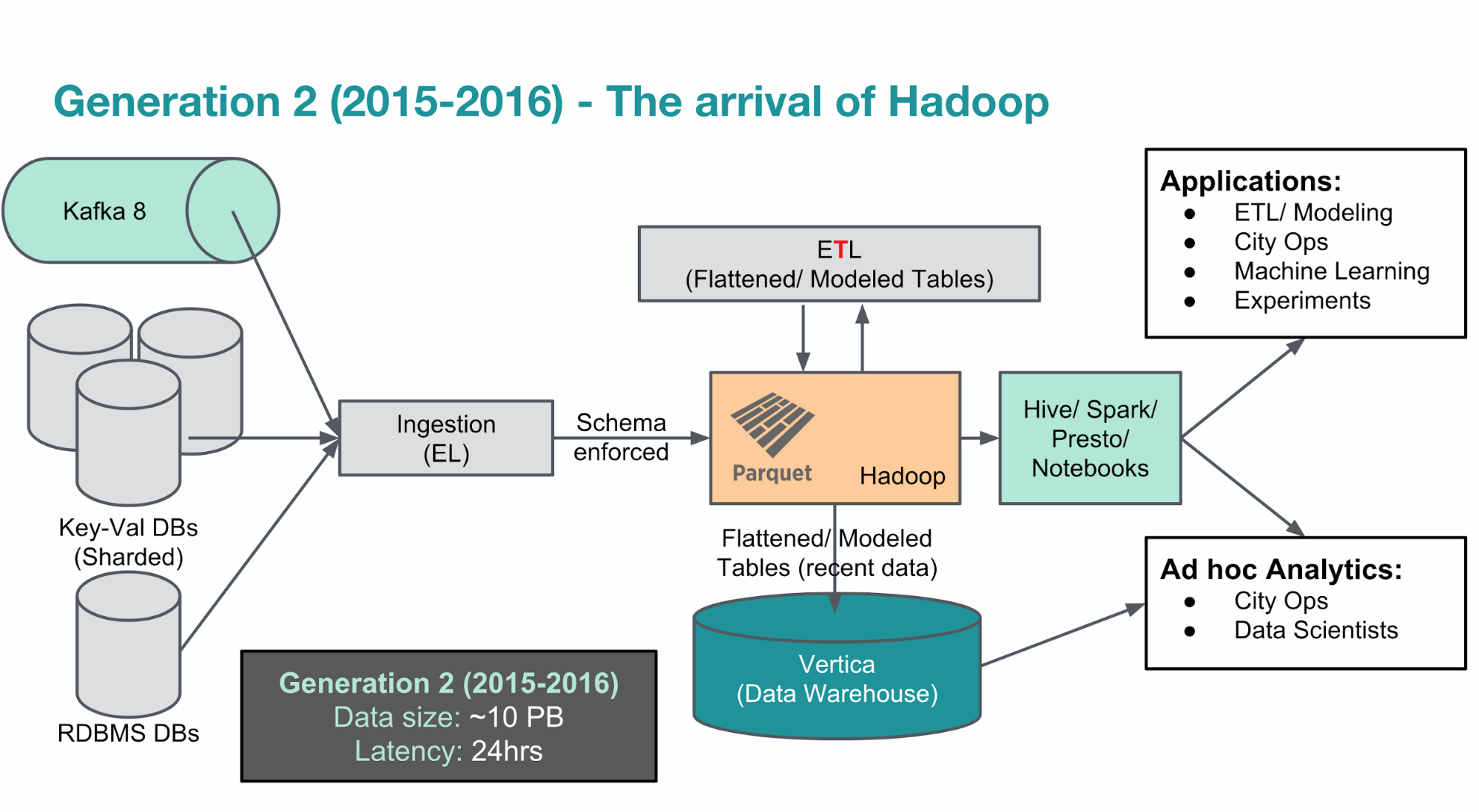
Download Open Data Platform Hadoop Images Congrelate
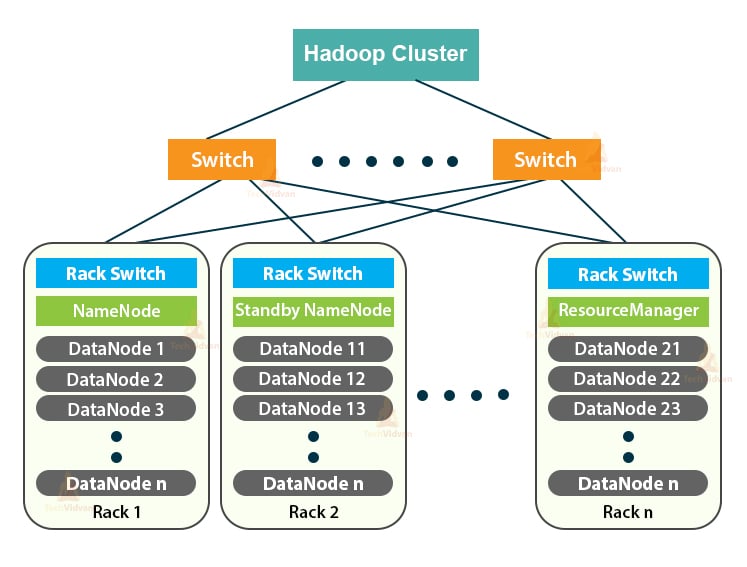
What Is Hadoop Cluster? Best Practices To Build Clusters


How To Use Eclipse Build Hadoop Plugin Youtube